Performing Arts Technology
School of Music, Theatre & Dance
University of Michigan
ude.hcimu@gnodwh
Stearns 131
Research
Content
- Overview
- CLIPSonic – Learning text-to-audio synthesis from videos
- CLIPSynth – Learning text-to-audio synthesis from videos
- Multitrack Music Transformer – Generating multitrack music with transformers
- CLIPSep – Learning text-queried sound separation with noisy videos
- Deep Performer – Score-to-audio music performance synthesis
- Arranger – Automatic instrumentation for solo music using deep learning
- Flow-based deep generative models
- MusPy – Open source Python library for music generation
- Music chord progression analysis
- DANTest – Understanding adversarial losses under a discriminative setting
- BinaryGAN – Modeling high-dimensional binary-valued data with GANs
- Pypianoroll – Open source Python library for handling multitrack piano rolls
- BinaryMuseGAN – Advancing binarization strategy of MuseGAN
- MuseGAN – Generating multitrack music with convolutional GANs
- Meow Meow – A smart pet interaction system
- A Stackelberg game model for user preference-aware resource pricing in cellular networks
- Reverse ordering in dynamical 2D hopper flow
- Point, Line and Plane – Extrema of area enclosed by a given curve and a variable line passing through a fixed point
- Analysis of gunmen’s strategies
- Squeeze! Don’t Move! – Tight configuration of disks and their circum-rectangle
This page is not actively maintained.
Overview
My research can be categorized into the following directions.
- Multitrack Music Generation
- MMT
(ICASSP 2023) - BinaryMuseGAN
(ISMIR 2018) - MuseGAN
(AAAI 2018)
- MMT
- Assistive Music Creation Tools
- Deep Performer
(ICASSP 2022) - Arranger
(ISMIR 2021)
- Deep Performer
- Multimodal Learning for Audio and Music
- Infrastructure for Music Generation Research
- MusPy
(ISMIR 2020) - Pypianoroll
(ISMIR LBD 2018)
- MusPy
CLIPSonic – Learning text-to-audio synthesis from videos
Collaborators: Xiaoyu Liu, Jordi Pons, Gautam Bhattacharya, Santiago Pascual, Joan Serrà, Taylor Berg-Kirkpatrick, Julian McAuley
In this work, we explore an alternative way of approaching bimodal learning for text and audio through leveraging the visual modality as a bridge. We propose the CLIPSonic model that can learn text-to-sound synthesis model using unlabeled videos and a pretrained language-vision model.
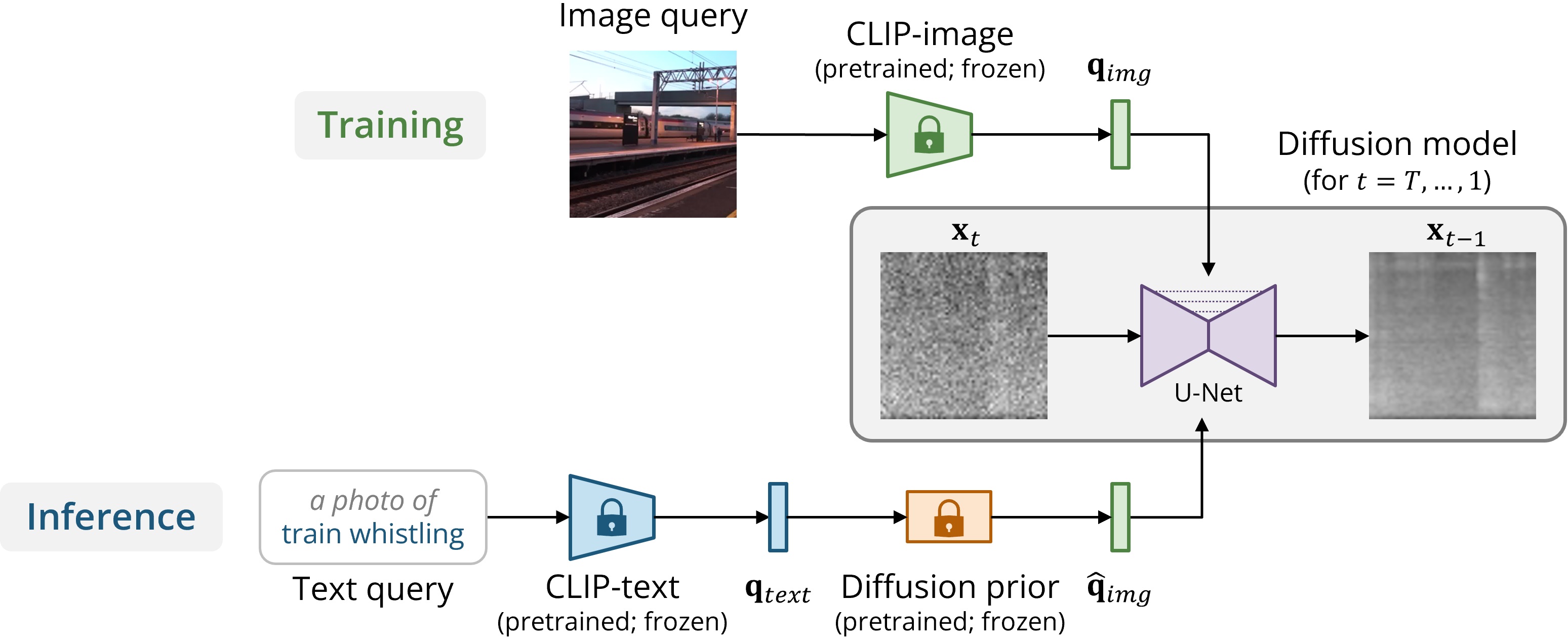
To learn more, please visit our project website.
CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
Hao-Wen Dong, Xiaoyu Liu, Jordi Pons, Gautam Bhattacharya, Santiago Pascual, Joan Serrà, Taylor Berg-Kirkpatrick, and Julian McAuley
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2023
paper demo video slides reviews
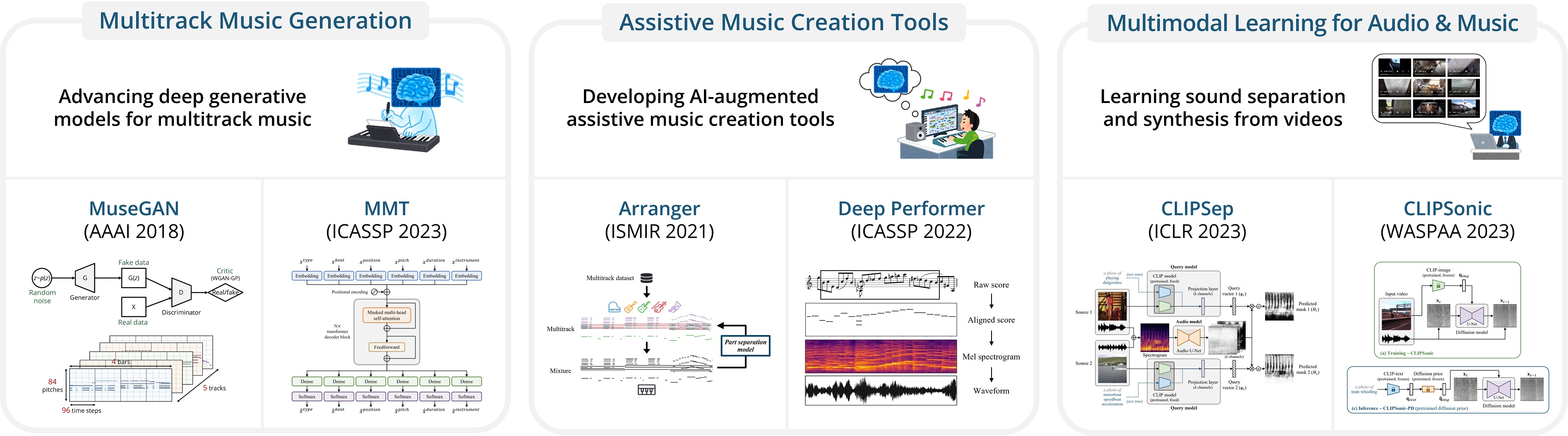
CLIPSynth – Learning text-to-audio synthesis from videos
Collaborators: Gunnar A. Sigurdsson, Chenyang Tao, Jiun-Yu Kao, Yu-Hsiang Lin, Anjali Narayan-Chen, Arpit Gupta, Tagyoung Chung, Jing Huang, Nanyun Peng, Wenbo Zhao
CLIPSynth is a novel text-to-sound synthesis model that can be trained using unlabeled videos and a pretrained language-vision model. CLIPSynth learns the desired audio-text correspondence by leveraging the visual modality as a bridge.
To learn more, please visit our project website.
CLIPSynth: Learning Text-to-audio Synthesis from Videos using CLIP and Diffusion Models
Hao-Wen Dong, Gunnar A. Sigurdsson, Chenyang Tao, Jiun-Yu Kao, Yu-Hsiang Lin, Anjali Narayan-Chen, Arpit Gupta, Tagyoung Chung, Jing Huang, Nanyun Peng, and Wenbo Zhao
CVPR Workshop on Sight and Sound (WSS), 2023
paper demo video slides
Multitrack Music Transformer – Generating multitrack music with transformers
Collaborators: Ke Chen, Shlomo Dubnov, Julian McAuley, Taylor Berg-Kirkpatrick
Multitrack Music Transformer (MMT) is a new transformer model that achieves comparable performance with state-of-the-art systems while achieving substantial speedups and memory reductions. MMT is based on a new multitrack music representation that allows a diverse set of instruments while keeping a short sequence length.

Here are some of the best samples generated by our proposed model.
To learn more, please visit our project website.
Multitrack Music Transformer
Hao-Wen Dong, Ke Chen, Shlomo Dubnov, Julian McAuley, and Taylor Berg-Kirkpatrick
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
paper demo video slides code reviews
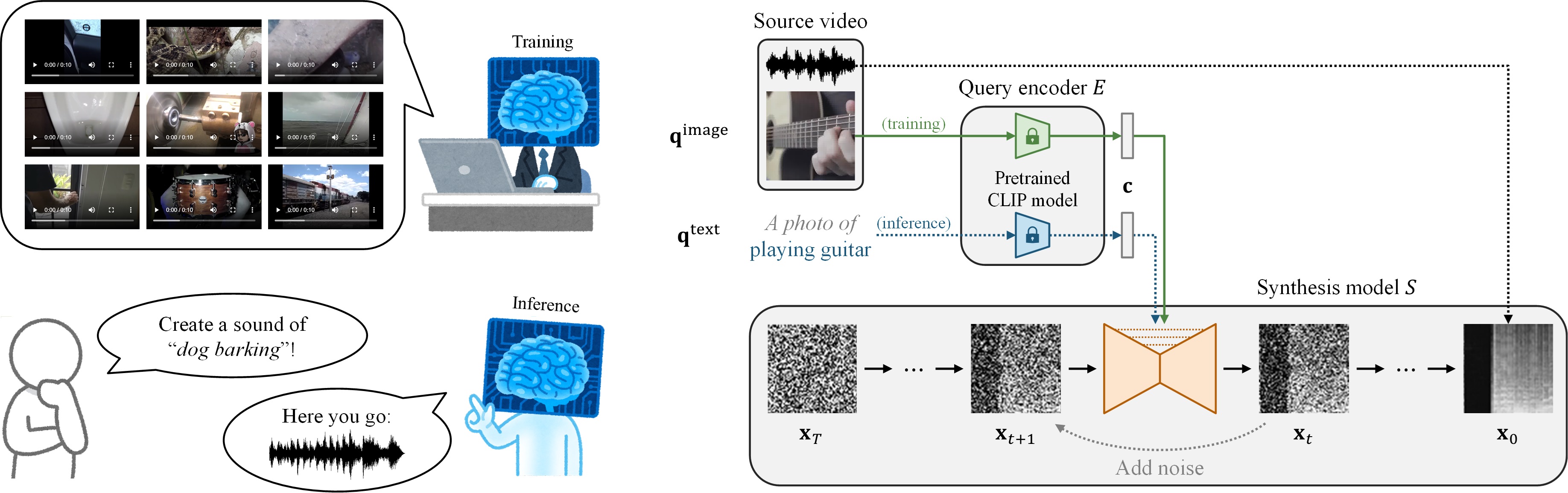
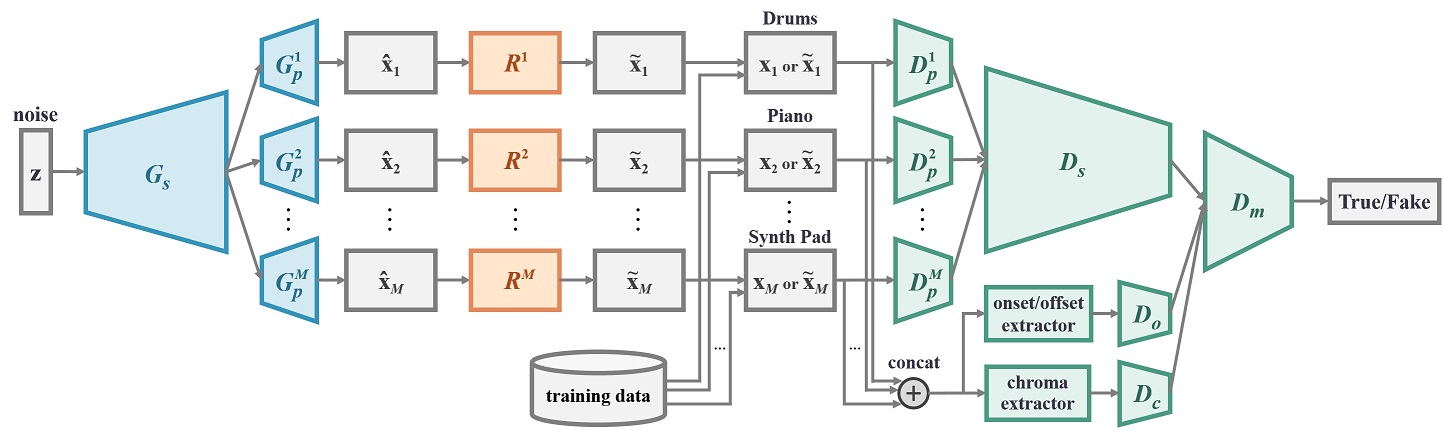
CLIPSep – Learning text-queried sound separation with noisy videos
Collaborators: Naoya Takahashi, Yuki Mitsufuji, Julian McAuley, Taylor Berg-Kirkpatrick
CLIPSep is a novel text-queried sound separation model that can be trained using unlabeled videos and a pretrained language-vision model. CLIPSep learns the desired audio-textual correspondence by leveraging the visual modality as a bridge. Further, we propose a new approach for training a query-based sound separation model with noisy data in the wild.
Here are some demos of the proposed model.
To learn more, please visit our project website.
Multitrack Music Transformer
Hao-Wen Dong, Ke Chen, Shlomo Dubnov, Julian McAuley, and Taylor Berg-Kirkpatrick
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
paper demo video slides code reviews
Deep Performer – Score-to-audio music performance synthesis
Collaborators: Cong Zhou, Taylor Berg-Kirkpatrick and Julian McAuley
Deep Performer is a novel three-stage system for score-to-audio music performance synthesis. It is based on a transformer encoder-decoder architecture commonly used in text-to-speech synthesis. In order to handle polyphonic music inputs, we propose a new polyphonic mixer for aligning the encoder and decoder. Moreover, we propose a new note-wise positional encoding for providing a fine-grained conditioning to the model so that the model can learn to behave differently at the beginning, middle and end of a note.
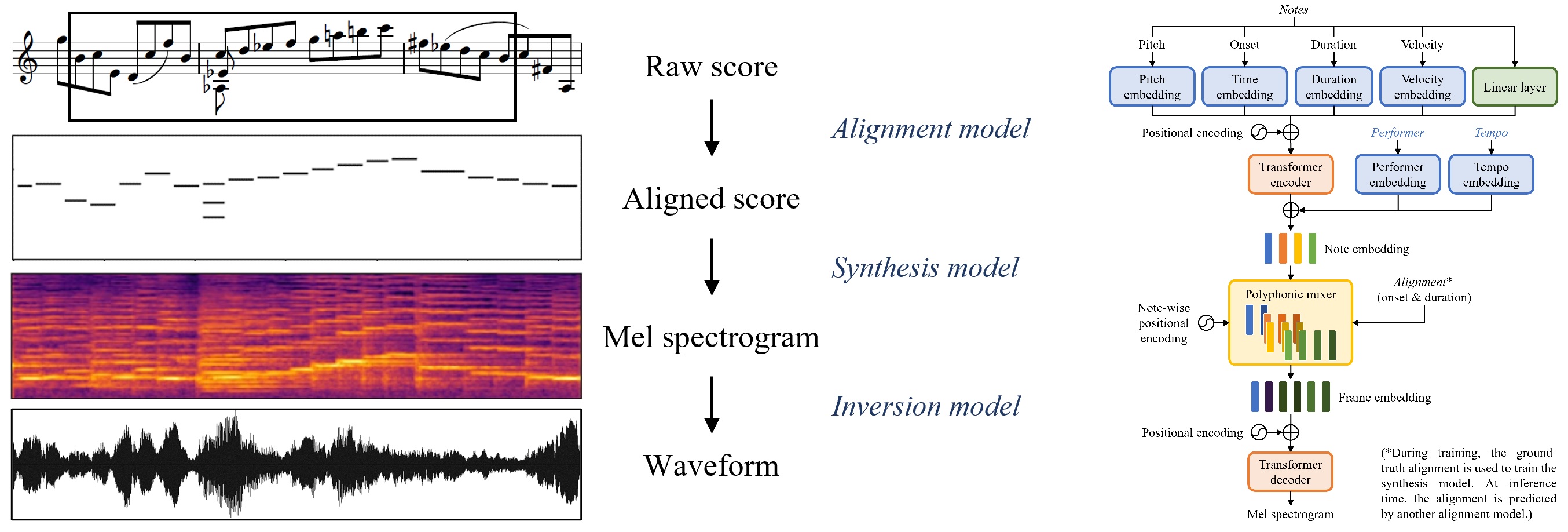
Here are some audio samples synthesized by our proposed system.
| Violin | Piano |
|---|---|
To learn more, please visit our project website.
Deep Performer: Score-to-Audio Music Performance Synthesis
Hao-Wen Dong, Cong Zhou, Taylor Berg-Kirkpatrick, and Julian McAuley
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
paper demo video slides poster reviews
Arranger – Automatic instrumentation for solo music using deep learning
Collaborators: Chris Donahue, Taylor Berg-Kirkpatrick, Julian McAuley
Arranger is a project on automatic instrumentation. We aim to dynamically assign a proper instrument for each note in solo music. Such an automatic instrumentation model could empower a musician to play multiple instruments on a keyboard at the same time. It could also assist a composer in suggesting proper instrumentation for a solo piece. Our proposed models outperform various baseline models and are able to produce alternative convincing instrumentations for existing arrangements.
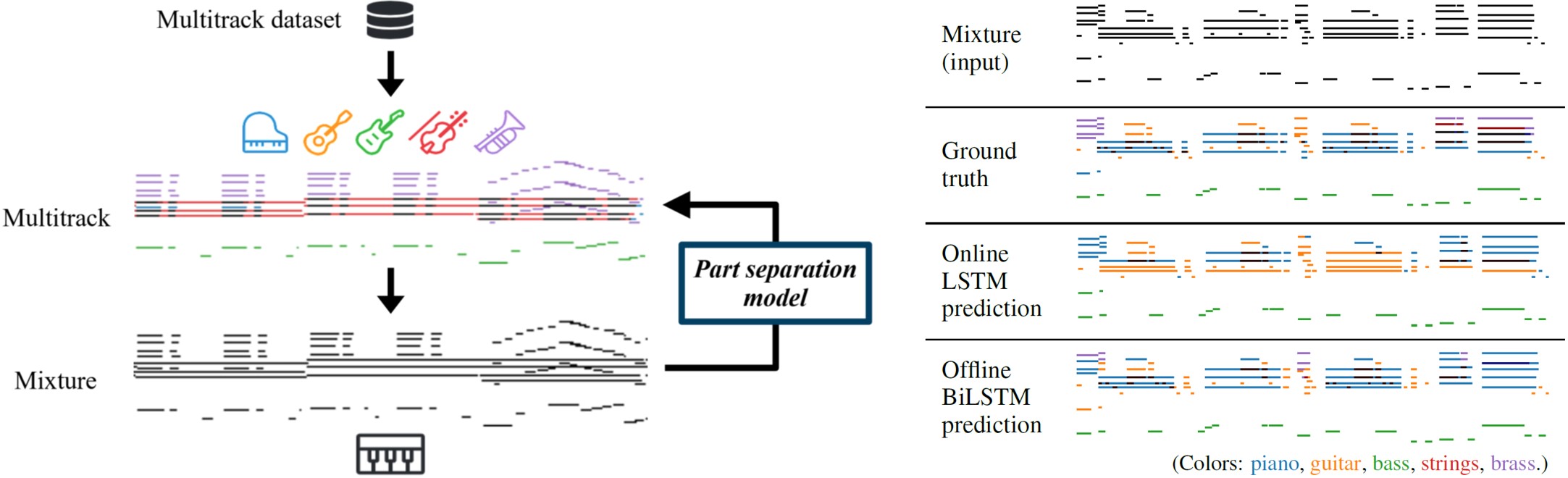
Here are some sample instrumentation produced by our system (more samples here).
| Mixture (input) | Predicted instrumentation |
|---|---|
| (guitar) | (piano, guitar, bass, strings, brass) |
To learn more, please visit our project website.
Towards Automatic Instrumentation by Learning to Separate Parts in Symbolic Multitrack Music
Hao-Wen Dong, Chris Donahue, Taylor Berg-Kirkpatrick, and Julian McAuley
International Society for Music Information Retrieval Conference (ISMIR), 2021
paper demo video slides code reviews
Flow-based Deep Generative Models
Collaborator: Jiarui Xu
We investigate the flow-based deep generative models. We first compare different generative models, especially generative adversarial networks (GANs), variational autoencoders (VAEs) and flow-based generative models. We then survey different normalizing flow models, including non-linear independent components estimation (NICE), real-valued non-volume preserving (RealNVP) transformations, generative flow with invertible 1×1 convolutions (Glow), masked autoregressive flow (MAF) and inverse autoregressive flow (IAF). Finally, we conduct experiments on generating MNIST handwritten digits using NICE and RealNVP to examine the effectiveness of flow-based models. For more details, please refer to the report and the slides (pdf).
MusPy – Open source Python library for music generation
Collaborators: Ke Chen, Julian McAuley, Taylor Berg-Kirkpatrick
MusPy is an open source Python library for symbolic music generation. It provides essential tools for developing a music generation system, including dataset management, data I/O, data preprocessing and model evaluation.
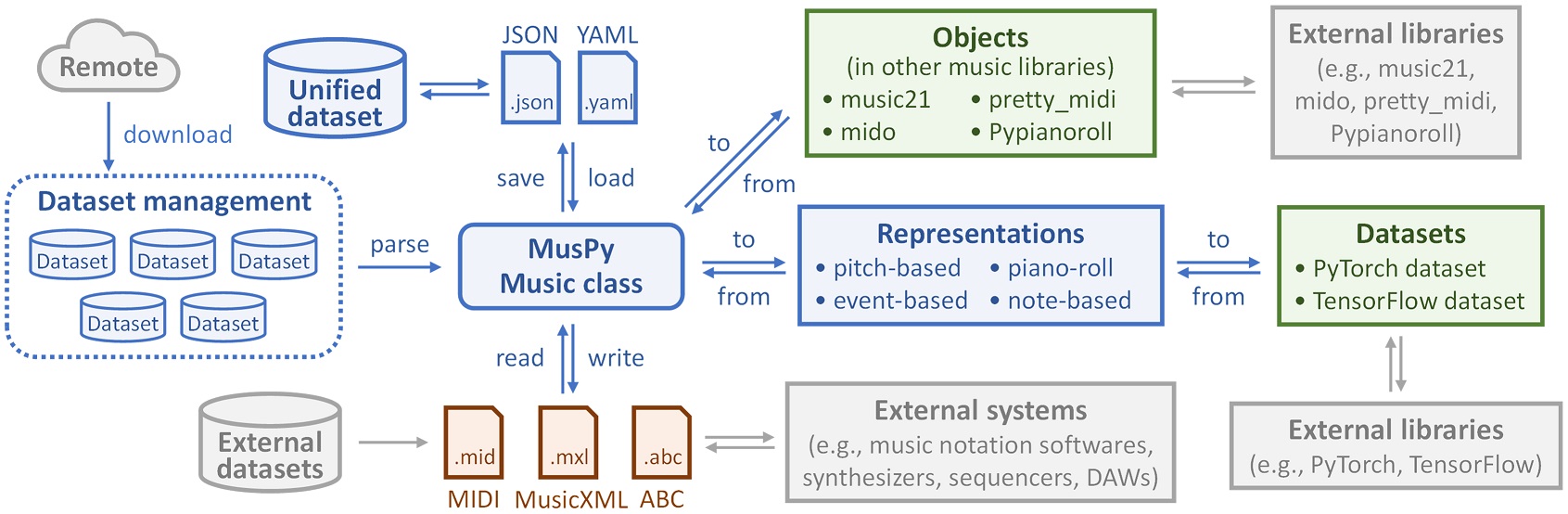
Features
- Dataset management system for commonly used datasets with interfaces to PyTorch and TensorFlow.
- Data I/O for common symbolic music formats (e.g., MIDI, MusicXML and ABC) and interfaces to other symbolic music libraries (e.g., music21, mido, pretty_midi and Pypianoroll).
- Implementations of common music representations for music generation, including the pitch-based, the event-based, the piano-roll and the note-based representations.
- Model evaluation tools for music generation systems, including audio rendering, score and piano-roll visualizations and objective metrics.
To learn more, please visit our project website.
MusPy: A Toolkit for Symbolic Music Generation
Hao-Wen Dong, Ke Chen, Julian McAuley, and Taylor Berg-Kirkpatrick
International Society for Music Information Retrieval Conference (ISMIR), 2020
paper video slides poster code documentation reviews
Music Chord Progression Analysis
Collaborator: Chun-Jhen Lai
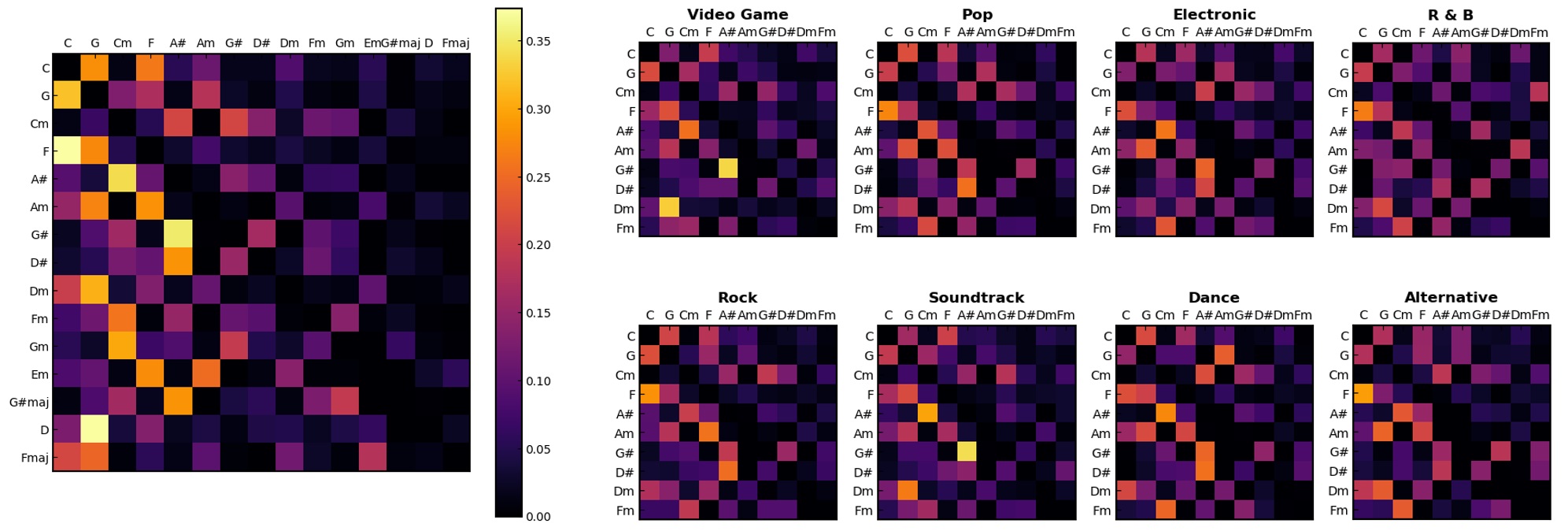
We analyze the statistical properties of chords and chord progressions in over ten thousand songs available on the HookTheory platform. In particular, we are interested in analyzing the prior probabilities for different chords, the transition probabilities between chords and chords and the most frequent chord progressions. We are also interested in how these statistics differ from genre to genre with an eye to reveal some interesting trends on the usage of chords and chord progressions in different genres. For more details, please refer to the report.
DANTest – Understanding adversarial losses under a discriminative setting
Collaborator: Yi-Hsuan Yang
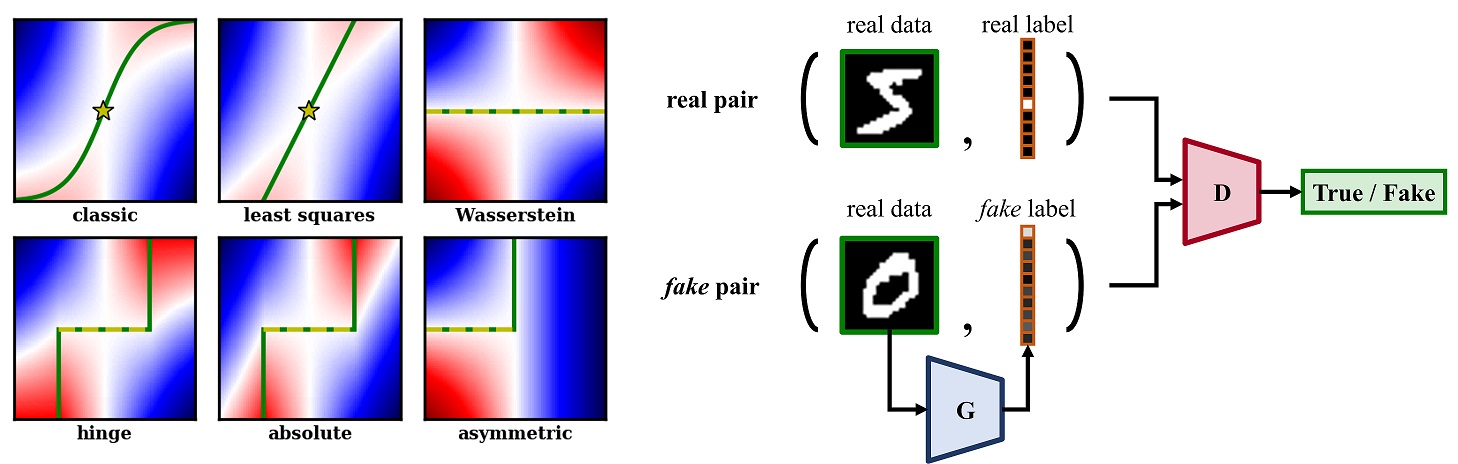
In this project, we aim to gain a deeper understanding of adversarial losses by decoupling the effects of their component functions and regularization terms. Specifically, we focus on the following two research questions:
- What certain types of component functions are theoretically valid adversarial loss functions?
- How different combinations of the component functions and the regularization approaches perform empirically against one another?
For the first question, we derive some necessary and sufficient conditions of the component functions such that the adversarial loss is a divergence-like measure between the data and the model distributions. For the second question, we propose a new, simple framework called DANTest for comparing different adversarial losses. With DANTest, we are able to decouple the effects of component functions and the regularization approaches.
To learn more about, please visit our project website.
On Output Activation Functions for Adversarial Losses: A Theoretical Analysis via Variational Divergence Minimization and An Empirical Study on MNIST Classification
Hao-Wen Dong and Yi-Hsuan Yang
arXiv preprint arXiv:1901.08753, 2019
paper demo code
BinaryGAN – Modeling high-dimensional binary-valued data with GANs{#binarygan}
Collaborator: Yi-Hsuan Yang
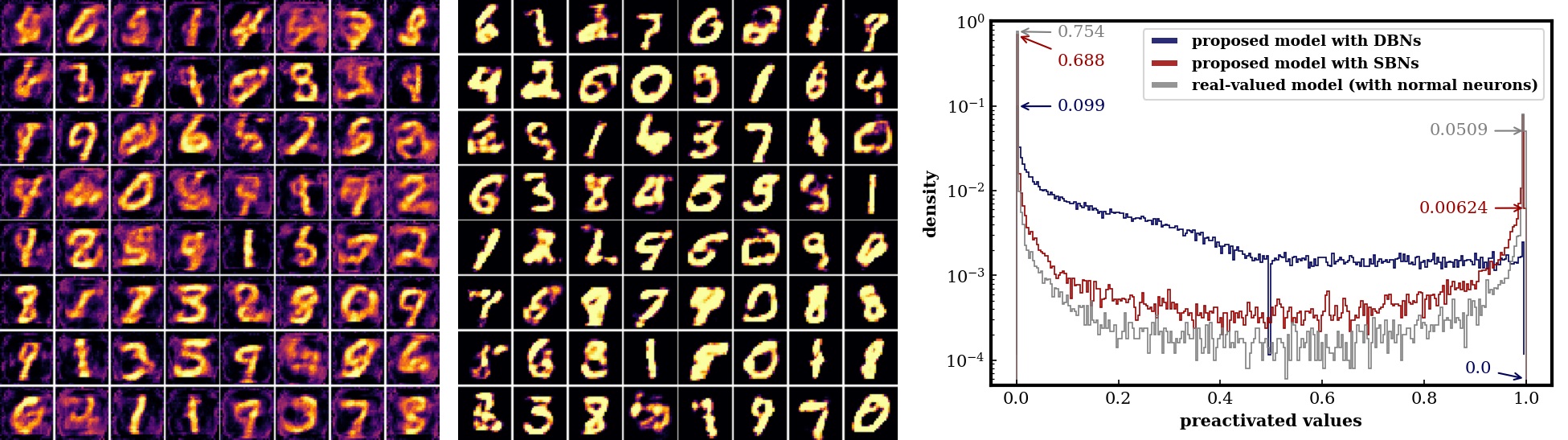
BinaryGAN is a novel generative adversarial network (GAN) that uses binary neurons at the output layer of the generator. We employ the sigmoid-adjusted straight-through estimators to estimate the gradients for the binary neurons and train the whole network by end-to-end backpropogation. The proposed model is able to directly generate binary-valued predictions at test time.
To learn more, please visit our project website.
Training Generative Adversarial Networks with Binary Neurons by End-to-end Backpropagation
Hao-Wen Dong and Yi-Hsuan Yang
arXiv preprint arXiv:1810.04714, 2018
paper demo slides code
Pypianoroll – Open source Python library for handling multitrack piano rolls
Collaborators: Wen-Yi Hsiao, Yi-Hsuan Yang
Pypianoroll is an open source Python library for working with piano rolls. It provides essential tools for handling multitrack piano rolls, including efficient I/O as well as manipulation, visualization and evaluation tools.

Features
- Manipulate multitrack piano rolls intuitively
- Visualize multitrack piano rolls beautifully
- Save and load multitrack piano rolls in a space-efficient format
- Parse MIDI files into multitrack piano rolls
- Write multitrack piano rolls into MIDI files
To learn more, please visit our project website.
Pypianoroll: Open Source Python Package for Handling Multitrack Pianorolls
Hao-Wen Dong, Wen-Yi Hsiao, and Yi-Hsuan Yang
ISMIR Late-Breaking Demos, 2018
paper poster code documentation
BinaryMuseGAN – Advancing binarization strategy of MuseGAN
Collaborator: Yi-Hsuan Yang
BinaryMuseGAN is a follow-up project of the MuseGAN project. In this project, we first investigate how the real-valued piano-rolls generated by the generator may lead to difficulties in training the discriminator for CNN-based models. To overcome the binarization issue, we propose to append to the generator an additional refiner network, which try to refine the real-valued predictions generated by the pretrained generator to binary-valued ones. The proposed model is able to directly generate binary-valued piano-rolls at test time.
We trained the network with training data collected from Lakh Pianoroll Dataset. We used the model to generate four-bar musical phrases consisting of eight tracks: Drums, Piano, Guitar, Bass, Ensemble, Reed, Synth Lead and Synth Pad. Audio samples are available here.
To learn more, please visit our project website.
Convolutional Generative Adversarial Networks with Binary Neurons for Polyphonic Music Generation
Hao-Wen Dong and Yi-Hsuan Yang
International Society for Music Information Retrieval Conference (ISMIR), 2018
paper demo video slides poster code reviews
MuseGAN – Generating multitrack music with convolutional GANs
Collaborators: Wen-Yi Hsiao, Li-Chia Yang, Yi-Hsuan Yang
MuseGAN is a project on music generation. In a nutshell, we aim to generate polyphonic music of multiple tracks (instruments). The proposed models are able to generate music either from scratch, or by accompanying a track given a priori by the user. We train the model with training data collected from Lakh Pianoroll Dataset to generate pop song phrases consisting of bass, drums, guitar, piano and strings tracks.
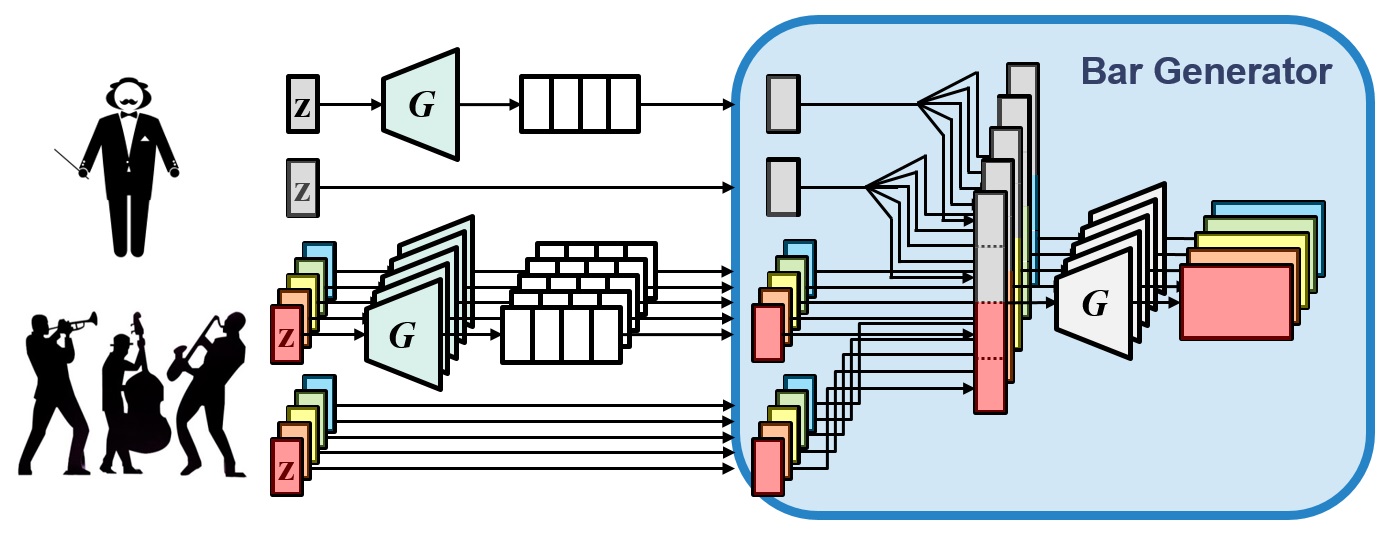
Check out some of the best samples generated by MuseGAN (more samples here).
To learn more, please visit our project website.
MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment
Hao-Wen Dong,* Wen-Yi Hsiao,* Li-Chia Yang, and Yi-Hsuan Yang (*equal contribution)
AAAI Conference on Artificial Intelligence (AAAI), 2018
paper demo slides code
Meow Meow – A Smart Pet Interaction System
Embedded Systems Labs (EE 3021), National Taiwan University, Spring 2017
Collaborator: Yu-Hsuan TengThis project is dedicated to our beloved Meow Meow (2005–2022).

Meow Meow is a smart pet interaction system that allows you to remotely interact with your pet(s) while monitoring the environment. We implement the system in Node.js and HTML/CSS with Tessel 2 boards, Socket.IO and Firebase. This is our final project for Embedded Systems Labs (EE 3021) at National Taiwan University in Spring 2017.
To learn more about Meow Meow, please visit our project website.
A Stackelberg game model for user preference-aware resource pricing in cellular networks
Undergraduate research at NTUEE
Collaborator: Hung-Yu Wei
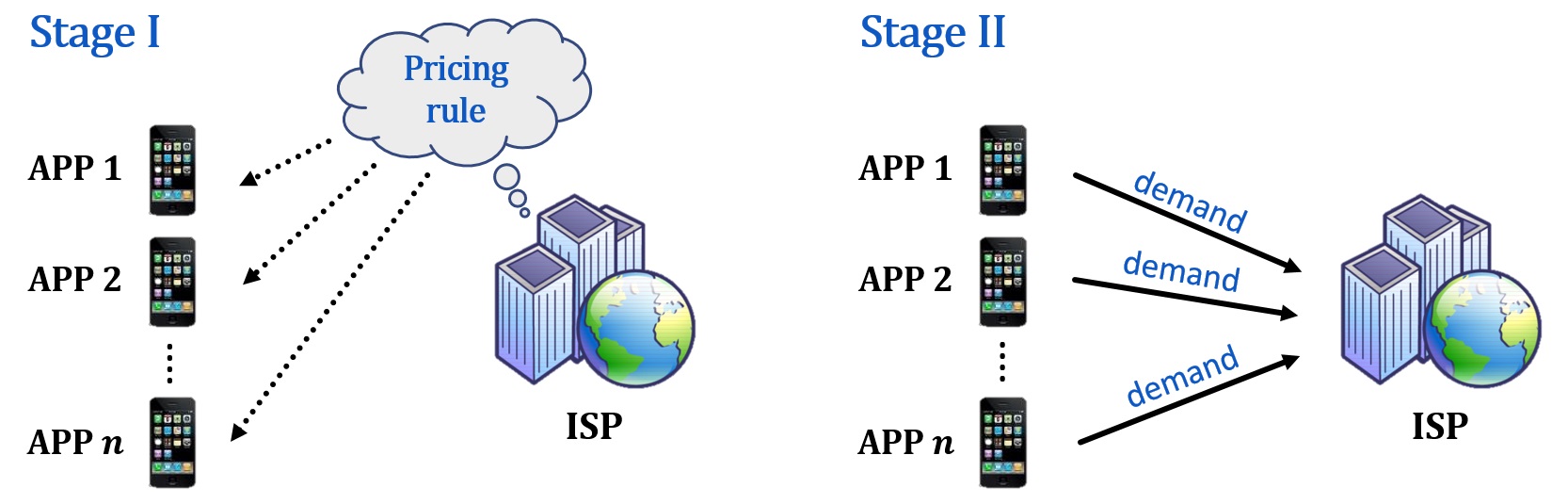
We study the user preference-aware resource pricing in wireless mobile networks. We model this problem as a two-stage Stackelberg game between multiple users and an internet service provider (ISP). We consider different user types and the users can have their own preferences on resource types. With such a game theoretical modeling, we are able to derive the optimal prices for different resource types for the ISP to maximize its profit.
For more information, please see these slides.
Reverse Ordering in Dynamical 2D Hopper Flow
High school science fair project in Physics
Collaborators: Chen-Chieh Ping, Kiwing To, Yu-Cheng Chien, Yan-Ping Zhang
We study the exit ordering of grains in gravity driven flow through two-dimensional hoppers of different hopper angle and outlet size with adjustable reclining angle. We observe a reverse ordering phenomenon such that grains entering the hopper at earlier times may not come out earlier. We record the entry order and exit order of the grains and calculate the degree of reverse ordering which is found to increase with increasing hopper angle, decreasing reclining angle, and increasing hopper outlet size.
In order to find the mechanism of reverse ordering, we construct maps which register the entry order and exit order according to the position of the grain in the hopper before the flow. By comparing the exit order map and the entry order map we locate the regions where grains undergo reverse ordering. From the trajectories of the grains in the reverse ordering regions, we find that they take part in avalanches at the surface on their way to the exit. Hence, it is the dynamical process of surface avalanche that reverse the exit order of the grain when they flow out of the hopper.
These results may be useful for special hopper design in agricultural and pharmaceutical industries to reduce or to enhance reverse ordering of materials for specific purposes.
Asia Pacific Conference of Young Scientists (APCYS), 2012 poster paper
Intel International Science and Engineering Fair (ISEF), 2012 paper poster
Taiwan International Science Fair (TISF), 2012 paper poster
Point, Line and Plane – Extrema of Area Enclosed by a Given Curve and a Variable Line Passing through a Fixed Point
High school science fair project in Mathematics
Collaborators: Yan-Ping Zhang, Chih-Chang Ou
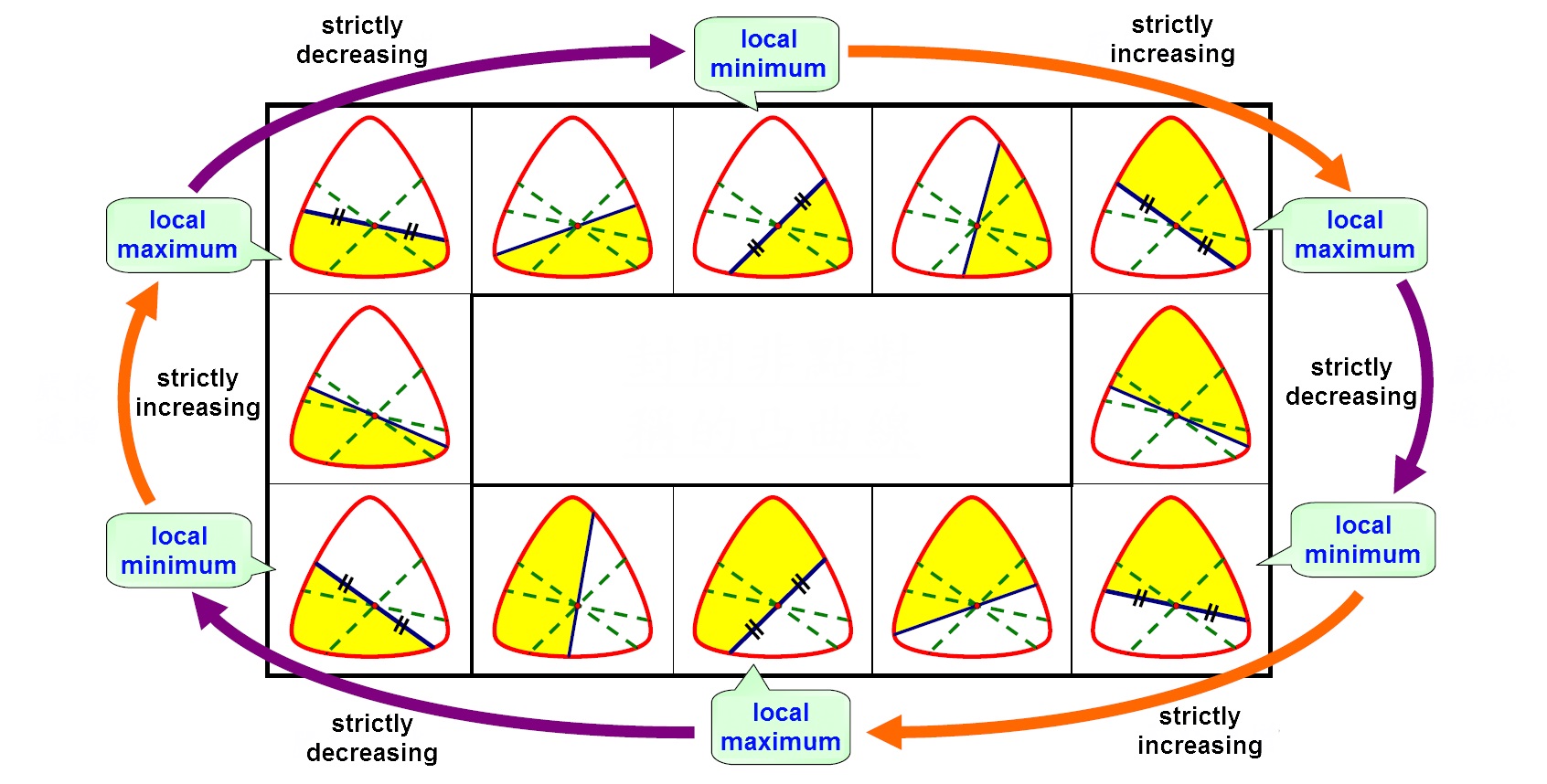
We study the properties of the segment and area enclosed by a given curve and a variable line passing through a fixed point. We first examine the existence of an equally dividing line in different settings. We then show that for a convex curve and a point inside it, the enclosed area between the curve and a variable line passing through the point results in extreme values if and only if the line is an equally dividing line. We also extend the analysis to nonconvex curves and we found that this property only holds when the curve can be written in an explicit function in polar form using the fixed point as the origin.
National Primary and High School Science Fair, Taiwan, 2011 paper poster slides
Analysis of Gunmen’s Strategies
High school science fair project in Mathematics
Collaborators: Chen-Chieh Ping, Chih-Chang Ou, Yan-Ping Zhang

We study a game among three gunmen with the following rules: 1) they play in turn without turns limitation, 2) in each turn, the player can either pass the turn or shoot one of the other two players, 3) the game ends when there is only one player alive and 4) the only remaining player is the winner. In this work, we consider the case when the three gunmen have their own precision and propose the decision box model for analyzing and visualizing their optimal strategies. We also extended our analysis to the imperfect information scenario.
Squeeze! Don’t Move! – Tight Configuration of Disks and their Circum-rectangle
High school science fair project in Mathematics
Collaborators: Chen-Chieh Ping, Sen-Peng Eu, Yan-Ping Zhang, Chih Chang Ou
We study the tight configurations for n disks of the same size in their circum-rectangles. We find the biggest and smallest such rectangles when n ≤ 6 and the smallest rectangle for arbitrary n of certain configurations. We also propose several approaches for generating interesting tight configurations of any number of disks based on simple ones.
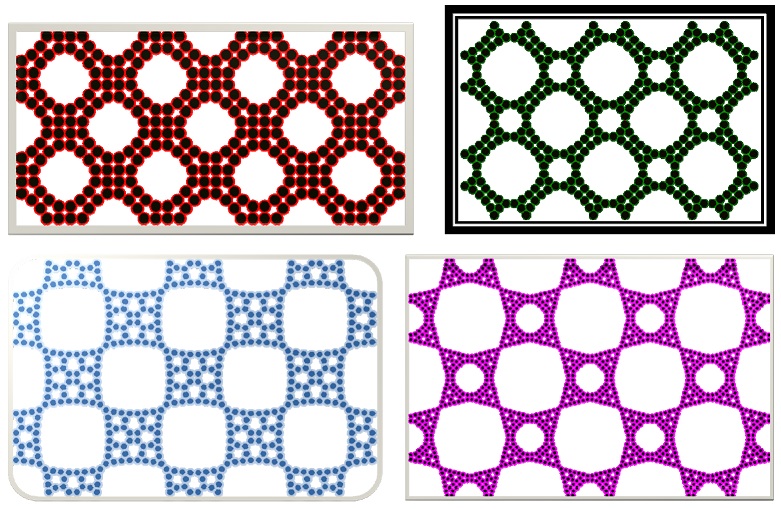
Canada-Wide Science Fair (CWSF), 2010 paper poster
Taiwan International Science Fair (TISF), 2010 paper