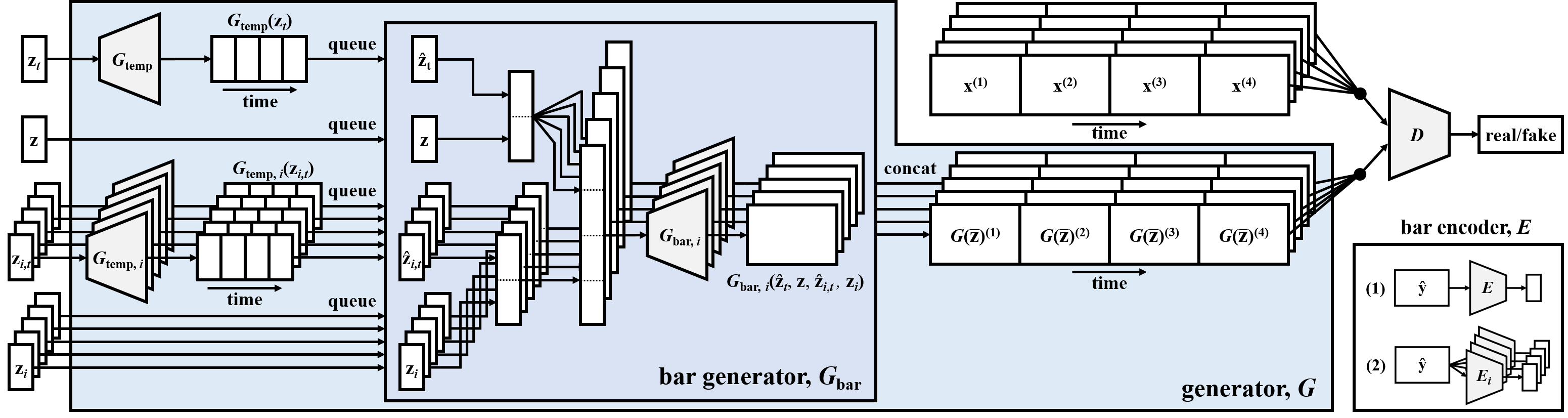
Model
The MuseGAN model consists of two parts: a multitrack model and a temporal model. The multitrack model is responsible for the multitrack interdependency, while temporal model handles the temporal dependency. We proposed three multitrack models according to three common compositional approaches. For the temporal model, we proposed one for generation from scratch and the other for accompanying a track given a priori by the user.
Modeling Multitrack Interdependency
In our experience, there are two common ways to create music.
- Given a group of musicians playing different instruments, they can create music by improvising music without a predefined arrangement, a.k.a. jamming.
- A composer arranges instruments with knowledge of harmonic structure and instrumentation. Musicians will then follow the composition and play the music.
We design three models corresponding to these compositional approaches.
Jamming model
Multiple generators work independently and generate music of its own track from a private random vector zi (i = 1 … M), where M denotes the number of generators (or tracks). These generators receive critics (i.e. backpropogated supervisory signals) from different discriminators.

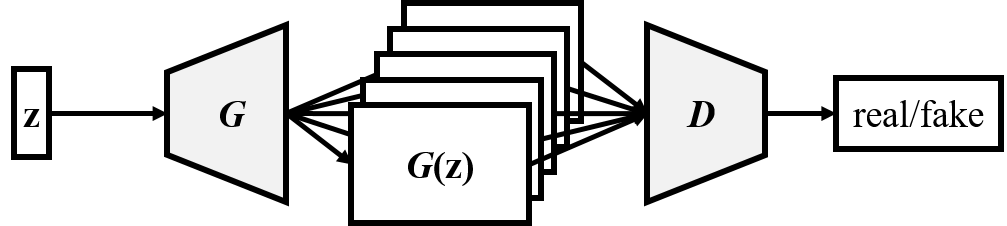
Composer model
One single generator creates a multi-channel pianoroll, with each channel representing a specific track. This model requires only one shared random vector z (which may be viewed as the intention of the composer) and one discriminator, which examines the M tracks collectively to tell whether the input music is real or fake.
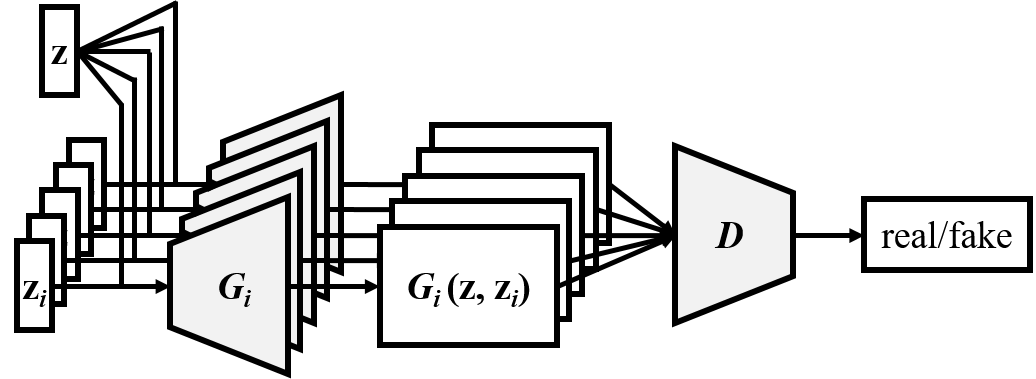
Hybrid model
Combining the idea of jamming and composing, the hybrid model require M generators and each takes as inputs an inter-track random vector z and an intra-track random vector zi. We expect that the inter-track random vector can coordinate the generation of different musicians, namely Gi, just like a composer does. Moreover, we use only one discriminator to evaluate the M tracks collectively.
A major difference between the composer model and the hybrid model lies in the flexibility—in the hybrid model we can use different network architectures (e.g., number of layers, filter size) and different inputs for the M generators. Therefore, we can for example vary the generation of one specific track without losing the inter-track interdependency.
Modeling Temporal Structure
Generation from scratch
The first method aims to generate fixed-length musical phrases by viewing bar progression as another dimension to grow the generator. The generator consists of two sub networks, the temporal structure generator Gtemp and the bar generator Gbar. Gtemp maps a noise vector to a sequence of some latent vectors, which is expected to carry temporal information and used by Gbar to generate pianorolls sequentially (i.e. bar by bar).

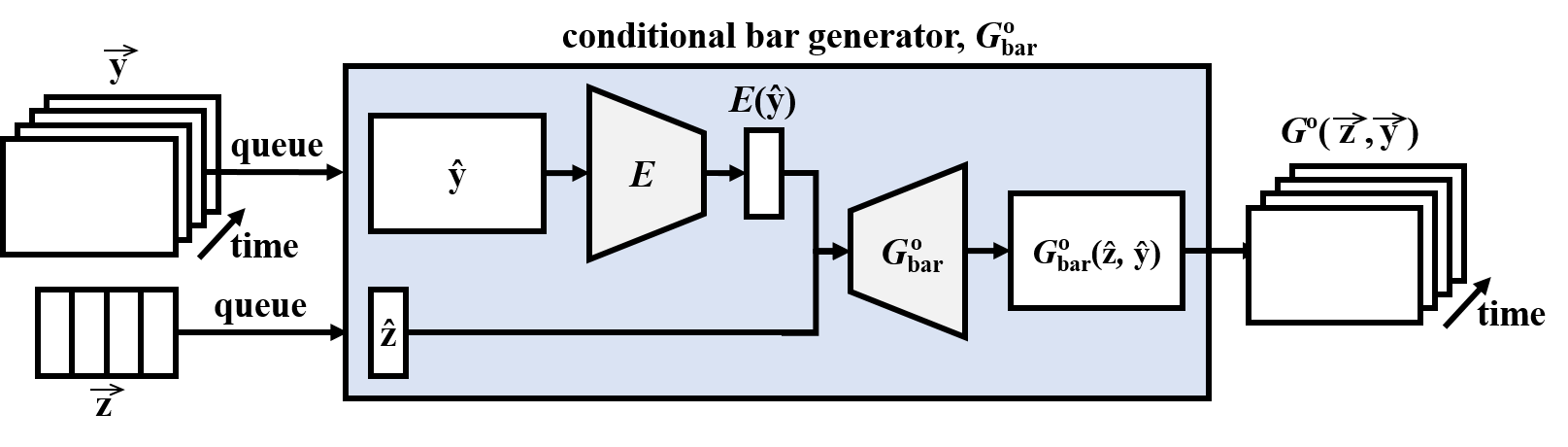
Track-conditional generation
The second method assumes that the bar sequence of one specific track is given by human, and tries to learn the temporal structure underlying that track and to generate the remaining tracks (and complete the song). The track-conditional generator G° generates bars one after another with the conditional bar generator, G°bar, which takes as inputs the conditional track and a random noise. In order to achieve such conditional generation with high-dimensional conditions, an additional encoder E is trained to map the condition to the space of z.
Note that the encoder is expected to extract inter-track features instead of intra-track features from the given track, since intra-track features are supposed not to be useful for generating the other tracks.
MuseGAN
MuseGAN, an integration and extension of the proposed multitrack and temporal models, takes as input four different types of random vectors:
- an inter-track time-independent random vector (z)
- an inter-track time-dependent random vectors (zt)
- M intra-track time-independent random vector (zi)
- M intra-track time-dependent random vectors (zi, t)
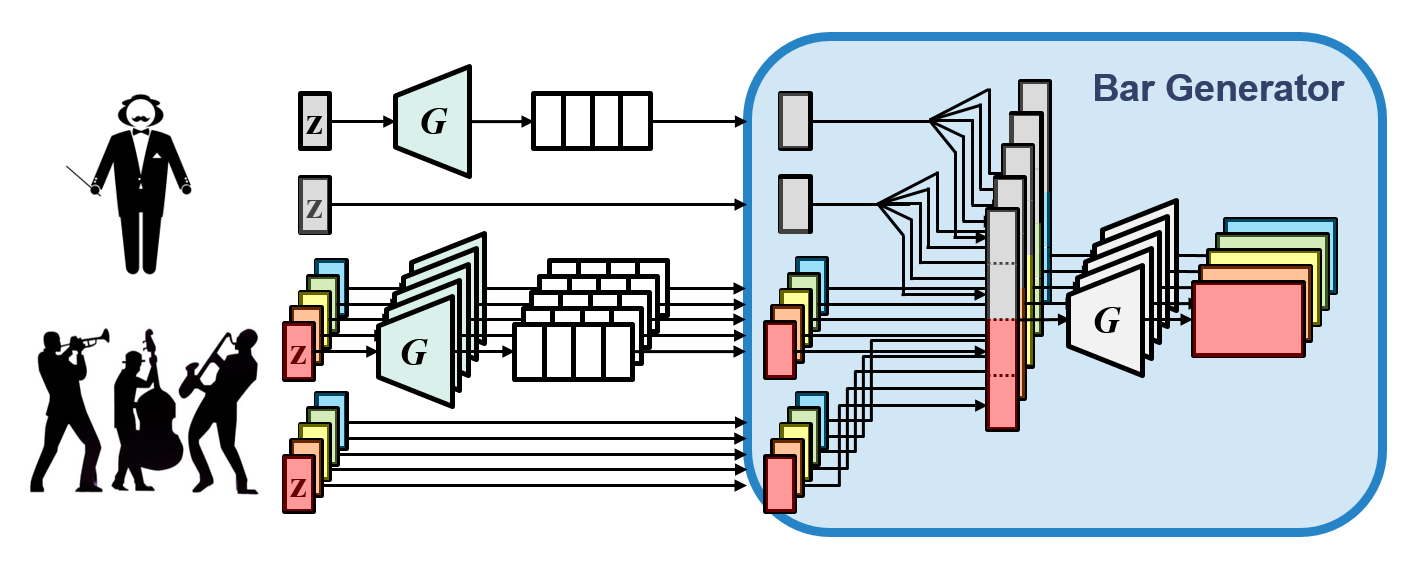
For track i (i = 1 … M), the shared temporal structure generator Gtemp and the private temporal structure generator Gtemp, i take the time-dependent random vectors, zt and zi, t, respectively, as their inputs, and each of them outputs a series of latent vectors containing inter-track and intra-track, respectively, temporal information. The output series (of latent vectors), together with the time-independent random vectors, z and zi, are concatenated and fed to the bar generator Gbar, which then generates pianorolls sequentially.
The following is the whole system diagram.