Getting Started with Great Lakes
Important Notes
- We can only use up to five GPUs as a whole at the same time. Please terminate your session when you finish your work so that others can access the GPUs.
- Delete your job if you finish before the time requested ends. You will only be charged for the time when the machine is up and running.
- The availability depends on the resource and the amount of time requested. If the wait time is too long, try reducing the requested time or switching to another partition.
- All the GPUs on Great Lakes are fast enough for most cases.
- If you’re not connected to MWireless, you must connect to U-M VPN to access Great Lakes.
Creating an ARC account
-
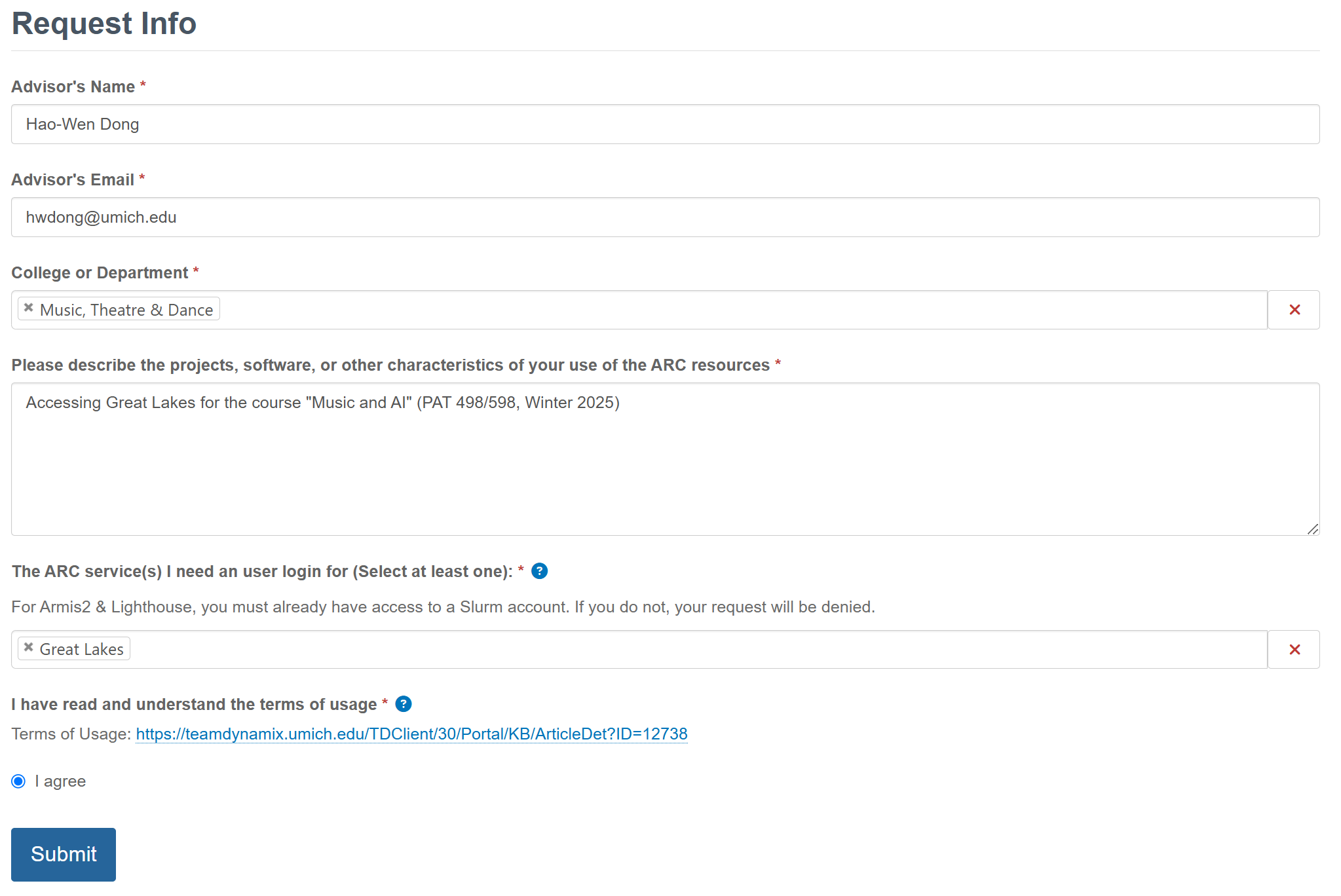
Request an HPC login here
Please put “Accessing Great Lakes for the course “Music and AI” (PAT 498/598, Winter 2025)” in the request.
-
Log into your account in the web portal
You must connect to U-M VPN to access Great Lakes if you’re not connected to MWireless.

Launching a Session
- Navigate to “Interactive Apps” in the web portal
-
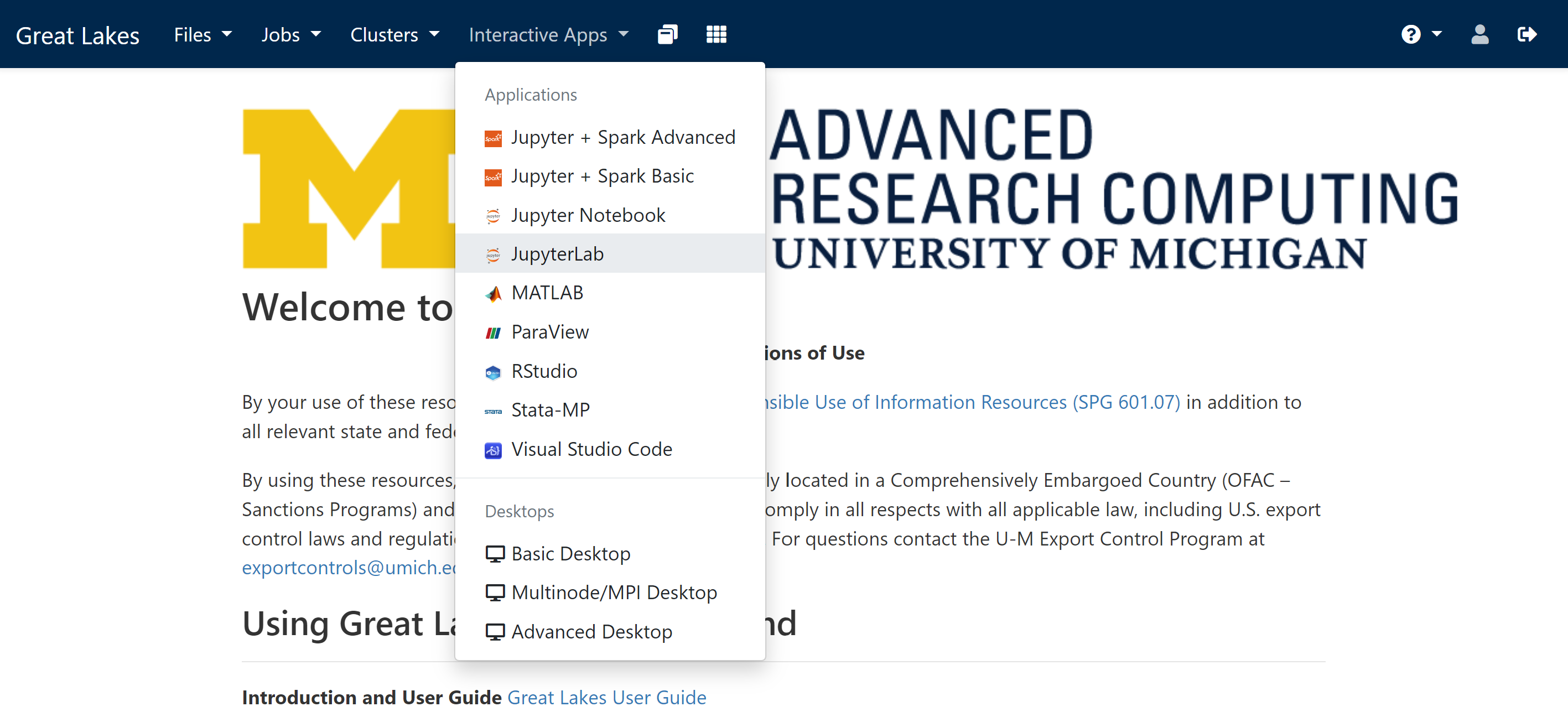
Select the application
You’ll likely want to select “JupyterLab” for the assignments.
-
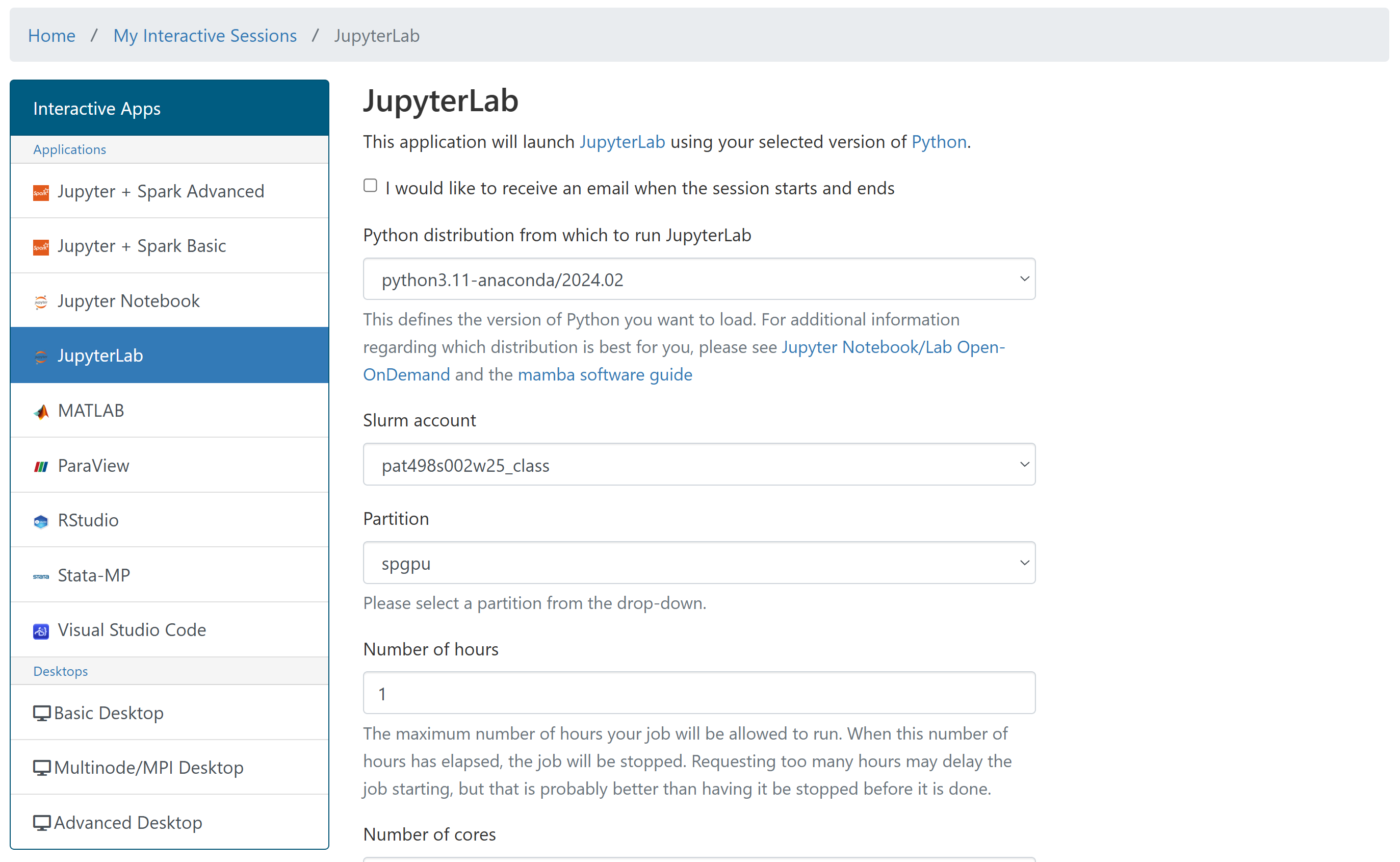
Specify the configuration of the instance (see below for suggestions)
If you’re unsure, select “python3.11-anaconda/2024.02” as your Python distribution.
Also, make sure to select the correct slurm account so that the cost is charged to the right account.
-
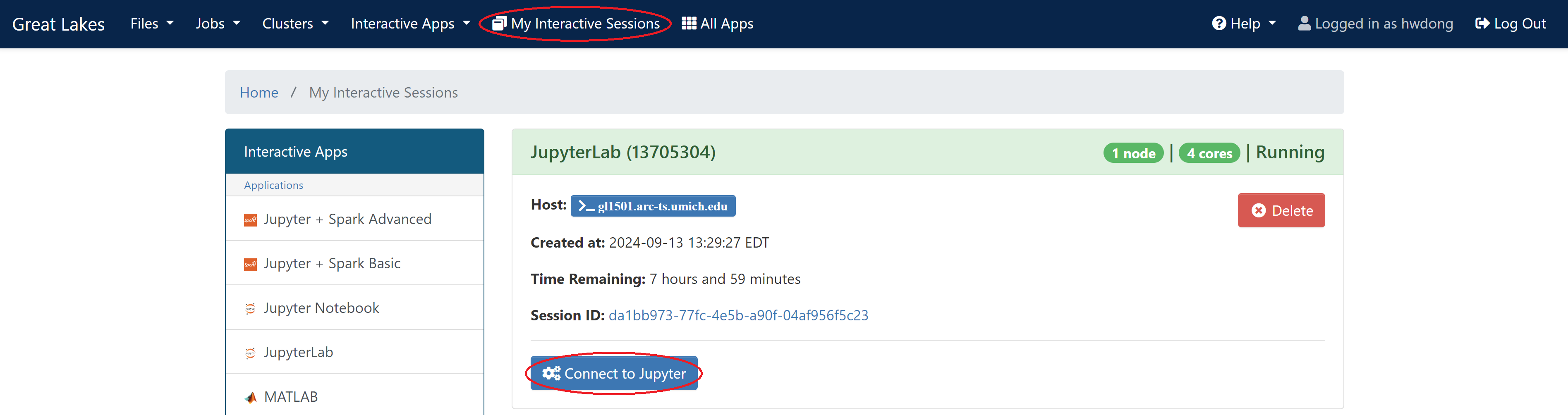
Connect to the launched instance
Configuration
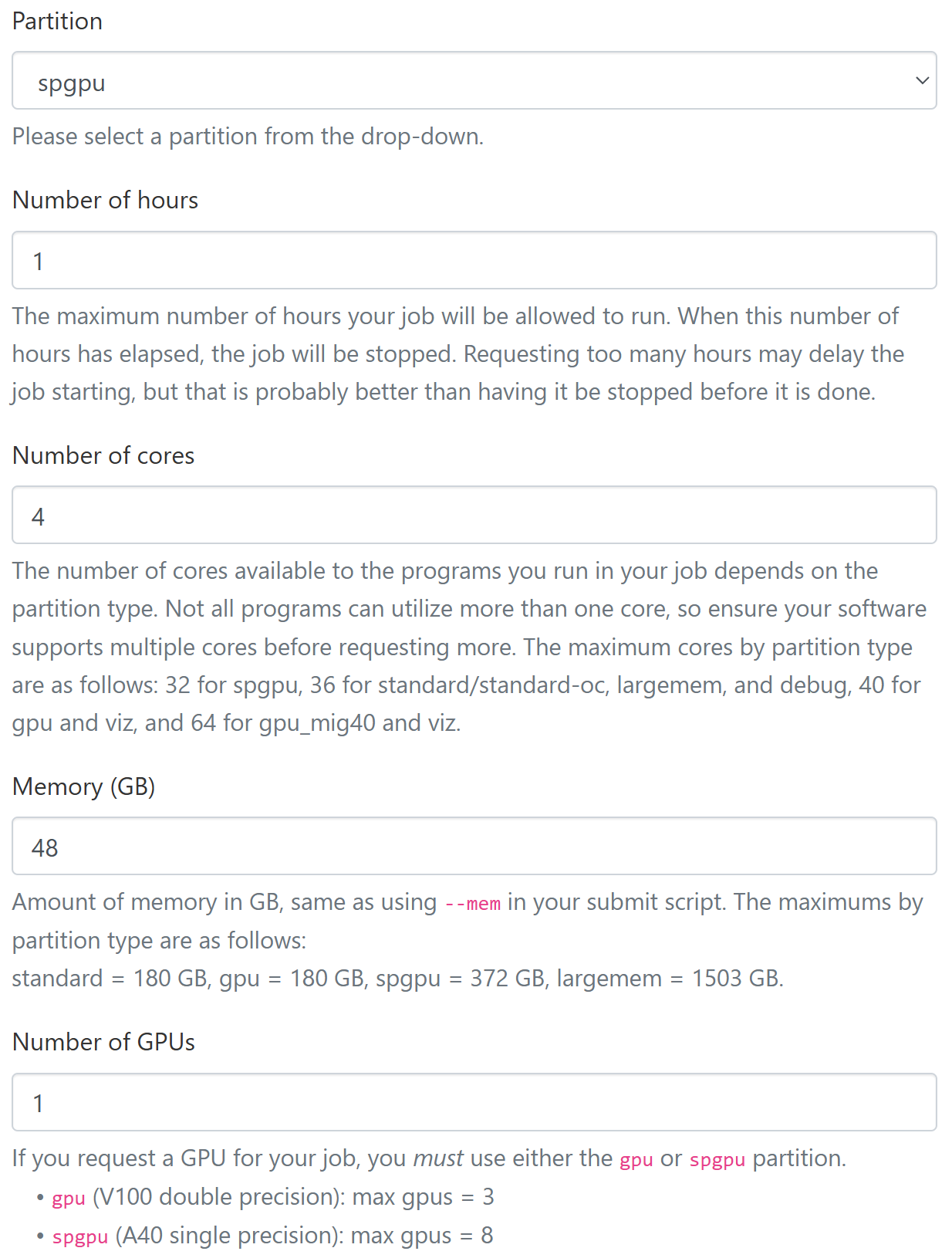
Recommended configuration for a GPU Machine
- Partition:
spgpu - Number of cores: 4
- Memory (GB): 48
Alternative configuration for a GPU Machine
- Partition:
gpu_mig40 - Number of cores: 8
- Memory (GB): 124
Another alternative configuration for a GPU Machine
- Partition:
gpu - Number of cores: 20
- Memory (GB): 90
Recommended configuration for a CPU-only machine
If you need more CPU cores on the
standardpartition, launch an instance with N cores with Nx7 GB of memory to maximize what you get.
- Partition:
standard - Number of cores: 4
- Memory (GB): 28
Other configurations
For each GPU requested, Great Lakes provides a certain number of CPU cores and RAM memory without additional charge. That’s why we need to configure the instance properly so that we are not getting less CPU and memory than charged.
Here is the configuration of each partition (as of Winter 2025; see the current configurations here):
| Partition | CPU cores | Memory (RAM) | GPU | GPU speed | GPU memory | #GPUs available |
|---|---|---|---|---|---|---|
| spgpu | 4 | 48 GB | A40 | faster | 48 GB | 224 |
| gpu_mig40 | 8 | 124 GB | A100 | fastest | 40 GB | 16 |
| gpu | 20 | 90 GB | V100 | fast | 16 GB | 52 |
| standard* | 1 | 7 GB | - | - | - | - |
Here is the cost for each partition (as of Winter 2025; see the current rates here):
| Partition | Hourly cost | CPU hours equivalent |
|---|---|---|
| spgpu | 0.11 | 7.33 |
| gpu_mig40 | 0.16 | 10.66 |
| gpu | 0.16 | 10.66 |
| standard* | 0.015 | 1 |
Storage
- Home directory: available at
/home/{UNIQUENAME}, 80 GB limit per user - Scratch space: available at
/scratch/hwdong_root/hwdong0/{UNIQUENAME}, 10TB limit as a whole (note that data in the scratch space may be removed if not used in 30 days)
Tips
Copied from https://sled-group.github.io/compute-guide/great-lakes
Sometimes you want to quickly launch a node and ssh into it instead of launching a whole JupyterLab session or remote desktop. In that case, you can put tail -f /dev/null as the last command of your job, which will prevent the job from exiting without eating up CPU cycles. For example, your job script might be something like:
#!/bin/bash
echo $SLURMD_NODENAME
tail -f /dev/null
Then, either use the web interface or inspect the $SLURMD_NODENAME environment variable to figure out the node name and simply ssh into it from your login machine.
If you prefer to interact with Great Lakes using command line, you might find this cheat sheet helpful.