Deep Performer
ICASSP 2022
Deep Performer: Score-to-Audio Music Performance Synthesis
Hao-Wen Dong1,2
Cong Zhou1
Taylor Berg-Kirkpatrick2
Julian McAuley2
1 Dolby Laboratories
2 University of California San Diego
* Work done during an internship at Dolby
paper demo video slides poster reviews
Content
Best samples
| Violin | Piano |
|---|---|
Datasets
We used two datasets to train our proposed system: Bach Violin Dataset for the violin and MAESTRO Dataset for the piano.
The Bach Violin Dataset is a collection of high-quality public recordings of Bach’s sonatas and partitas for solo violin (BWV 1001–1006). The dataset consists of 6.5 hours of professional recordings from 17 violinists recorded in various recording setups. It also provides the reference scores and estimated alignments between the recordings and scores. Below is an example of the alignment provided, where white dots and green lines show the estimated note onsets and durations.
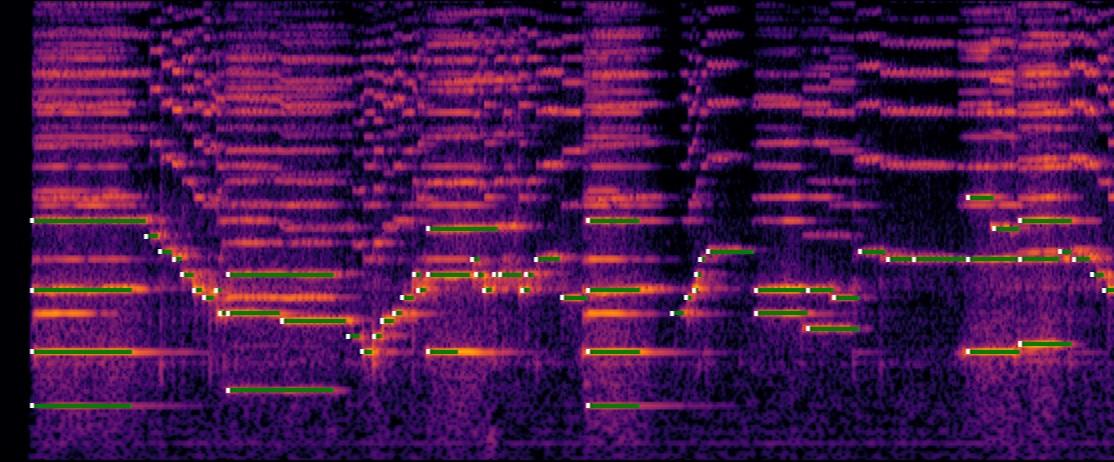
For more information, please visit the project website for the Bach Violin Dataset.
Violin samples
These are the violin samples used in the subjective listening test. We used the Bach Violin Dataset to train our models.
(V1) Bach - Violin Partita no. 1 in B minor, BWV 1002, mov. 2 - Emil Telmányi
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(V2) Bach - Violin Partita no. 1 in B minor, BWV 1002, mov. 2 - Emil Telmányi
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(V3) Bach - Violin Partita No. 3 in E major, BWV 1006, mov. 1 - Emil Telmányi
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(V4) Bach - Violin Partita No. 3 in E major, BWV 1006, mov. 4 - Karen Gomyo
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(V5) Bach - Violin Partita No. 3 in E major, BWV 1006, mov. 7 - Oliver Colbentson
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
Piano samples
These are the piano samples used in the subjective listening test. We used the MAESTRO Dataset to train our models.
(P1) International Piano-e-Competition 2006
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(P2) International Piano-e-Competition 2008
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(P3) International Piano-e-Competition 2009
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(P4) International Piano-e-Competition 2011
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
(P5) International Piano-e-Competition 2013
| Baseline | |
| Deep Performer (ours) | |
| - w/o note-wise positional encoding | |
| - w/o performer embedding | |
| - w/o encoder (using piano roll input) |
Audios for the figures on the paper
Figure 1
An overview of the proposed three-stage pipeline for score-to-audio music performance synthesis.
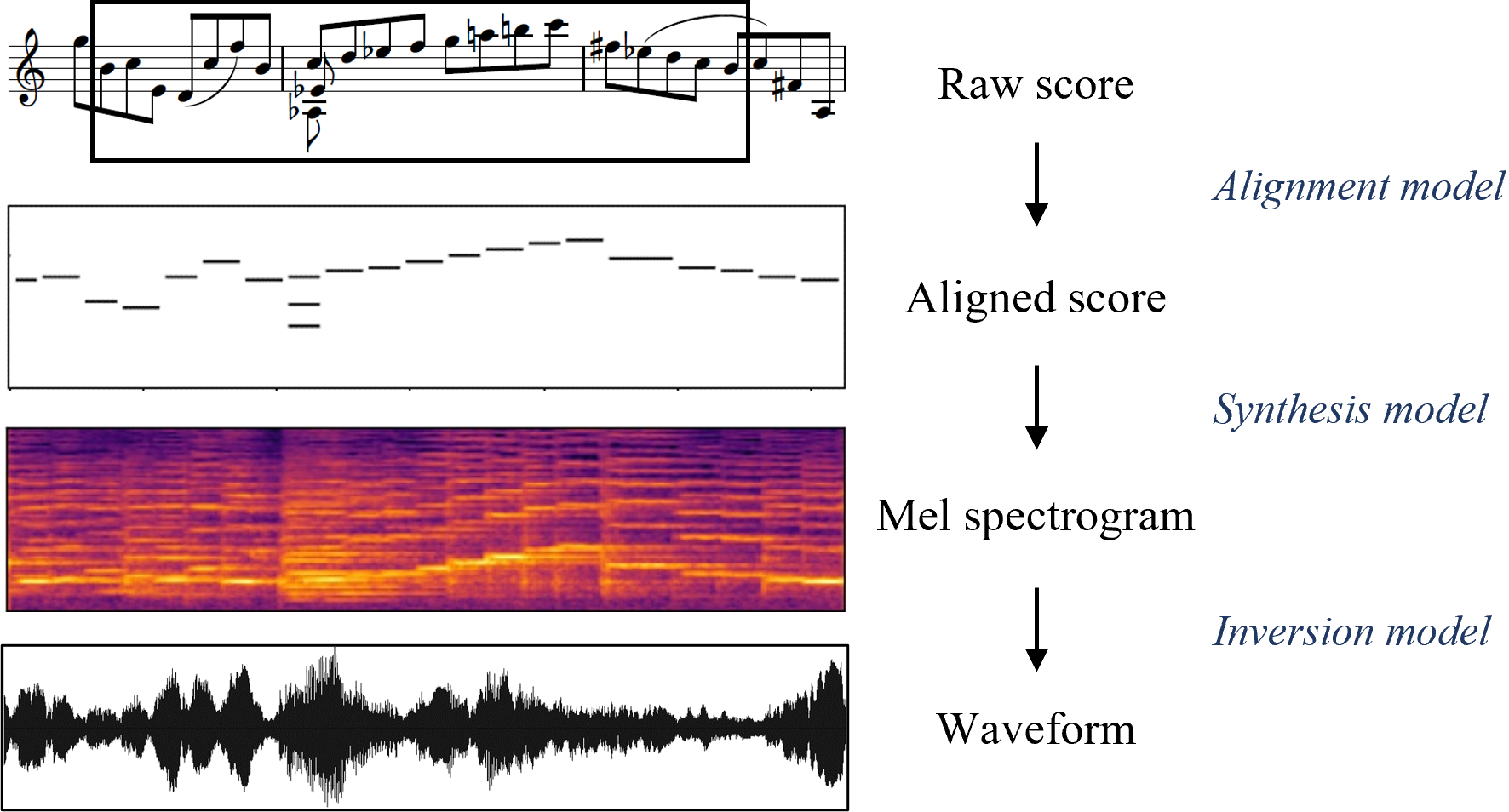
Figure 3
An example of the constant-Q spectrogram of the first 20 seconds of a violin recording and the estimated onsets (white dots) and durations (green lines).
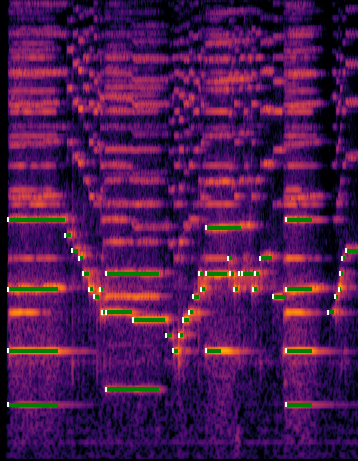
Figure 5
Examples of the mel spectrograms, in log scale, synthesized by our proposed model for (a) violin and (c) piano. (b) and (d) show the input scores for (a) and (c), respectively.
| (a) | 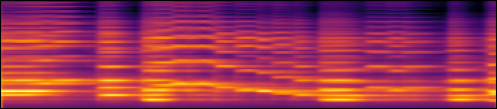 |
| (b) |  |
| (c) | 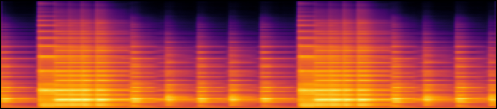 |
| (d) |  |
Figure 6
Examples of the mel spectrograms, in log scale, synthesized by (a) the baseline model, (b) our proposed synthesis model, and (d) our proposed synthesis model without the note-wise positional encoding. (c) and (e) show the waveforms for (b) and (d), respectively. (f) shows the input score.
| (a) | 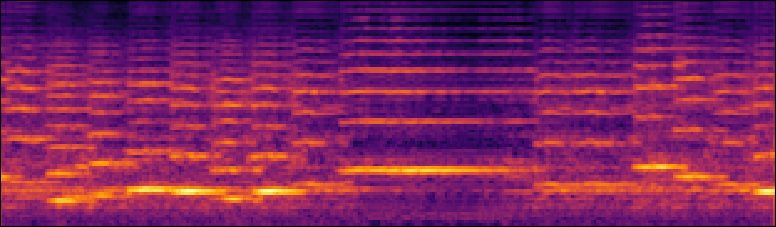 |
| (b) | 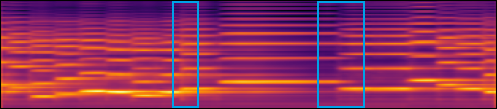 |
| (c) |  |
| (d) | 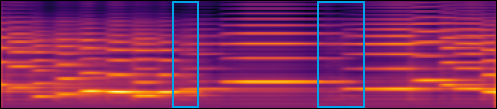 |
| (e) |  |
Citation
Hao-Wen Dong, Cong Zhou, Taylor Berg-Kirkpatrick, and Julian McAuley, “Deep Performer: Score-to-Audio Music Performance Synthesis,” Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022.
@inproceedings{dong2022deepperformer,
author = {Hao-Wen Dong and Cong Zhou and Taylor Berg-Kirkpatrick and Julian McAuley},
title = {Deep Performer: Score-to-Audio Music Performance Synthesis},
booktitle = {Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = 2022,
}