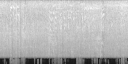
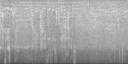
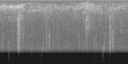
CLIPSynth: Our proposed model (trained with image queries).
CLIPSynth-Text: The proposed CLIPSynth model trained with text queries.
CLIPSynth-Hybrid: The proposed CLIPSynth trained with both image and text queries.
MiniLMSynth: The proposed CLIPSynth model with the query model replaced by a MiniLM encoder.
CLIPRetriever: A retrieval-based model that finds the associated audio of the image that has the closest CLIP embedding to the input text query.
Model
Generative
Unlabeled data only
Query type (training)
Query type (test)
CLIPSynth
✓
✓
Image
Text
CLIPSynth-Text
✓
Text
Text
CLIPSynth-Hybrid
✓
Image + Text
Text
MiniLMSynth
✓
Text
Text
CLIPRetriever
✓
-
Text
Important notes
For the CLIPSynth models, we prefix the text query into the form of “a photo of playing {query}” on MUSIC and “a photo of {query}” on VGG-Sound.
All the spectrograms shown are mel spectrograms.
Example results on MUSIC
All the examples presented in this section use text queries, and they are randomly selected samples.
Examples
bassoon
cello
pipa
acoustic guitar
electric bass
erhu
piano
erhu
bagpipe
guzheng
bassoon
bagpipe
drum
flute
cello
clarinet
acoustic guitar
erhu
pipa
guzheng
Comparison 1
Query: “bassoon”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 2
Query: “cello”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 3
Query: “pipa”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 4
Query: “acoustic guitar”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 5
Query: “electric bass”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Example results on VGG-Sound
All the examples presented in this section use text queries, and they are randomly selected samples.
Examples
people crowd
people sniggering
goat bleating
baby laughter
sharpen knife
playing marimba, xylophone
car engine starting
playing sitar
sliding door
engine accelerating, revving, vroom
child speech, kid speaking
train horning
helicopter
male speech, man speaking
dog bow-wow
ambulance siren
playing acoustic guitar
dog barking
bowling impact
pigeon, dove cooing
Comparison 1
Query: “people crowd”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 2
Query: “people sniggering”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 3
Query: “goat bleating”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 4
Query: “baby laughter”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Comparison 5
Query: “sharpen knife”
CLIPSynth
CLIPSynth-Text
CLIPSynth-Hybrid
MiniLMSynth
CLIPRetriever
Image-queried Synthesis Demo
All the examples presented in this section use image queries, and they are randomly selected samples.
Examples on MUSIC
Examples on VGG-Sound
Out-of-distribution Generalization Experiments
In this experiment, we aim to examine the generalizability of the trained CLIPSynth model with unseen objects and combinatory prompts.
Experiment on CLIPSynth trained on MUSIC
Note: We can see that the model can generalize to unseen objects to some extent (viola, double bass, marimba, bongos are not presented in the MUSIC dataset). However, the model fails to handle combinatory inputs but generate the “average” sounds instead.
Experiment on CLIPSynth trained on VGG-Sound
Citation
Hao-Wen Dong, Gunnar A. Sigurdsson, Chenyang Tao, Jiun-Yu Kao, Yu-Hsiang Lin, Anjali Narayan-Chen, Arpit Gupta, Tagyoung Chung, Jing Huang, Nanyun Peng, and Wenbo Zhao, “CLIPSynth: Learning Text-to-audio Synthesis from Videos using CLIP and Diffusion Models,” Proceedings of the CVPR Workshop on Sight and Sound, 2023.
@inproceedings{dong2023clipsynth,author={Hao-Wen Dong and Gunnar A. Sigurdsson and Chenyang Tao and Jiun-Yu Kao and Yu-Hsiang Lin and Anjali Narayan-Chen and Arpit Gupta and Tagyoung Chung and Jing Huang and Nanyun Peng and Wenbo Zhao},title={CLIPSynth: Learning Text-to-audio Synthesis from Videos using CLIP and Diffusion Models},booktitle={Proceedings of the CVPR Workshop on Sight and Sound},year=2023,}